
Reading time: 19 min
AI FinOps for Agencies: LLM Routing, Cost Control, and Human Review
A practical guide to AI FinOps for agencies: how to control LLM costs, route tasks across models, protect quality, and price AI automation work responsibly.
An agency can build a working AI automation demo in a weekend and still lose money after the first real client starts using it.
The reason is simple: production AI work is not priced by the excitement of the demo. It is priced by task volume, model calls, context size, retries, tool usage, review time, support work, and the quality standard the client expects.
That is why the serious version of AI service delivery is not AI arbitrage. It is AI FinOps: the discipline of understanding, forecasting, controlling, and improving the cost of AI workflows without quietly lowering quality.
For an agency, AI FinOps answers practical questions:
- Which model should handle this task?
- When should a request be escalated to a stronger model?
- When is human review required?
- What does one successful task actually cost?
- Which workflows are profitable after retries, monitoring, and support?
- How do we price the service without promising impossible savings?
This article explains how agencies can use LLM routing, cost per task, prompt caching, quality gates, and human review to build AI automation services that are financially predictable and safe enough for real clients.
Why “AI Arbitrage” Is the Wrong Mental Model
The phrase AI arbitrage sounds like a shortcut: buy cheap model output, sell it as expensive business value, keep the margin. That framing may work for shallow content farms, but it is weak for serious client work.
A business does not pay for cheap tokens. It pays for a result: a lead qualified, a ticket routed, an invoice checked, a document summarized, a CRM record cleaned, a report prepared, or a follow-up drafted.
The agency’s job is not to hide cheap AI behind expensive packaging. The agency’s job is to design a reliable workflow where the right parts are automated, the risky parts are reviewed, and the cost structure stays visible.
That is a much more durable business. It also creates better content and better SEO context than generic 'make money with AI' advice. The commercial ecosystem around AI FinOps includes cloud platforms, model providers, observability tools, model gateways, evaluation platforms, automation software, CRM systems, and consulting services.
Cost Per Task Is More Important Than Cost Per Token
Tokens matter, but they are not the main business metric. The useful metric is cost per successful task.
A lead summary that costs $0.08 in model usage but needs five minutes of human cleanup may be more expensive than a $0.25 summary that is ready to approve. A support triage workflow that uses a small model but retries three times may cost more than routing the ticket to a stronger model once.
A practical cost-per-task model includes:
-
Human baseline cost
How much time the workflow takes today, who performs it, and what their loaded hourly cost is. -
Model execution cost
Input tokens, output tokens, model choice, retries, tool calls, structured extraction, and any fallback model calls. -
Infrastructure cost
Databases, vector storage, queues, logs, monitoring, API gateways, background workers, and hosting. -
Review cost
Human approval time for low-confidence, high-risk, or client-facing outputs. -
Maintenance cost
Prompt updates, evaluation sets, bug fixes, integration changes, client support, and reporting. -
Business value
Faster response time, lower backlog, cleaner records, fewer missed leads, better routing, or reduced manual work.
The question is not 'How cheap can we make this model call?' The question is 'What does one accepted, useful, reviewed outcome cost?'
The Basic AI FinOps Formula
A simple agency formula looks like this:
Workflow margin = client price per task - total cost per successful task
But the total cost has more parts than many agencies expect:
Total cost per successful task = model cost + tool cost + infrastructure cost + retry cost + review cost + support cost + failure cost
Failure cost matters. If an automation creates a bad CRM note, routes a high-value lead to the wrong team, sends a weak client-facing message, or misses an exception, someone has to fix it. That correction time belongs in the margin model.
For example, imagine an agency sells a support ticket triage workflow. Each ticket goes through classification, retrieval, summarization, priority scoring, and a draft internal note. The visible LLM cost may look tiny. But the real cost includes logs, monitoring, client-specific rules, review queues, support requests, and edge cases where the system needs a stronger model.
AI FinOps makes those hidden costs visible before they destroy the project margin.
LLM Routing: Use the Cheapest Model That Safely Works
LLM routing means sending each task to the model or route that fits its complexity, risk, and quality requirement.
The goal is not to use the smallest model everywhere. The goal is to stop using the most expensive model by default.
A good routing policy considers:
- task type;
- required accuracy;
- output risk;
- context length;
- latency target;
- customer tier;
- confidence score;
- whether the result is internal or client-facing;
- whether a human will review the output.
Routine extraction, formatting, tagging, deduplication, and short summaries may work with cheaper models. Complex reasoning, executive-facing writing, legal/financial wording, architecture decisions, or ambiguous tasks often need a stronger model and human review.
A simple routing table can look like this:
| Task type | Cheap model | Premium model | Human review |
|---|---|---|---|
| Lead summary | Yes | Sometimes | Selective |
| CRM deduplication | Yes | Sometimes | Selective |
| Support ticket tagging | Yes | Sometimes | Selective |
| Blog outline | Yes | Sometimes | Yes |
| Code refactor | Sometimes | Yes | Yes |
| Legal or financial copy | No | Yes | Required |
| Customer-facing complaint response | Sometimes | Yes | Required |
| Executive report | No | Yes | Required |
This table is not universal. Each agency needs its own routing policy based on real evaluation data. But the principle is stable: low-risk routine tasks can be optimized for cost; high-risk tasks should be optimized for correctness and reviewability.
A Practical Routing Architecture
A production routing system does not have to be complicated at the beginning. It can start with rules and become more intelligent over time.
A practical architecture has six steps:
-
Classify the task
Is this extraction, summarization, routing, coding, decision support, research, or client-facing writing? -
Estimate risk
Is the output internal or external? Can a mistake be corrected easily? Does the task touch legal, financial, medical, security, or customer-sensitive information? -
Choose the first route
Select the cheapest model or workflow that historically meets the quality bar for this task type. -
Apply quality gates
Check whether the output is complete, structured correctly, grounded in the provided data, and free of obvious policy or formatting issues. -
Fallback when needed
Retry with a stronger model, request more context, shorten the task, or send the item to a human queue. -
Log the outcome
Track model, route, cost, latency, confidence, review decision, and final result.
The last step is easy to skip, but it is what turns routing from guesswork into AI FinOps. Without logs, the agency cannot know which routes are profitable or which outputs are quietly failing review.
Quality Gates Protect Both Margin and Trust
A cheap answer that fails review is not cheap. It creates rework.
Quality gates are checks that decide whether an output can move forward. They can be simple rules, model-based evaluations, structured validations, or human checks.
Useful quality gates include:
- required fields are present;
- JSON matches the expected schema;
- citations or source references are included when required;
- confidence is above the threshold;
- the output does not contain unsupported claims;
- the recommendation is based on provided context;
- the tone matches the client’s standard;
- the task does not require escalation.
For example, a lead routing agent might fail the quality gate if it cannot identify company size, if there is a possible duplicate account, or if the lead is attached to a high-value opportunity. In that case, the right answer is not another cheap model call. The right answer may be escalation to a stronger model or a human reviewer.
This is how agencies avoid the common trap of optimizing for token cost while damaging client trust.
Prompt Caching and Stable Context
Prompt caching is one of the most practical cost and latency controls for repeated AI workflows. The basic idea is simple: if many requests reuse the same long instructions, examples, schemas, or tool definitions, the provider may be able to process that repeated prefix more efficiently.
This changes how agencies should design prompts. Repeated content should stay stable. Variable content should come later.
A good structure is:
- Stable system instructions.
- Stable workflow rules.
- Stable output schema.
- Stable examples.
- Client-specific policy snippets if needed.
- Variable task data.
Bad prompt design constantly changes the entire prompt, which makes caching less useful and makes behavior harder to compare. Better prompt design keeps the reusable prefix stable and injects only the task-specific data that changes.
Other token controls include:
- using structured outputs instead of long prose where possible;
- limiting retrieved context;
- summarizing long documents before deeper reasoning;
- avoiding repeated boilerplate in every call;
- batching offline jobs;
- using shorter model outputs for internal workflows;
- storing intermediate summaries when they are safe to reuse.
Cost optimization should never mean removing the context required for quality. The goal is to remove waste, not evidence.
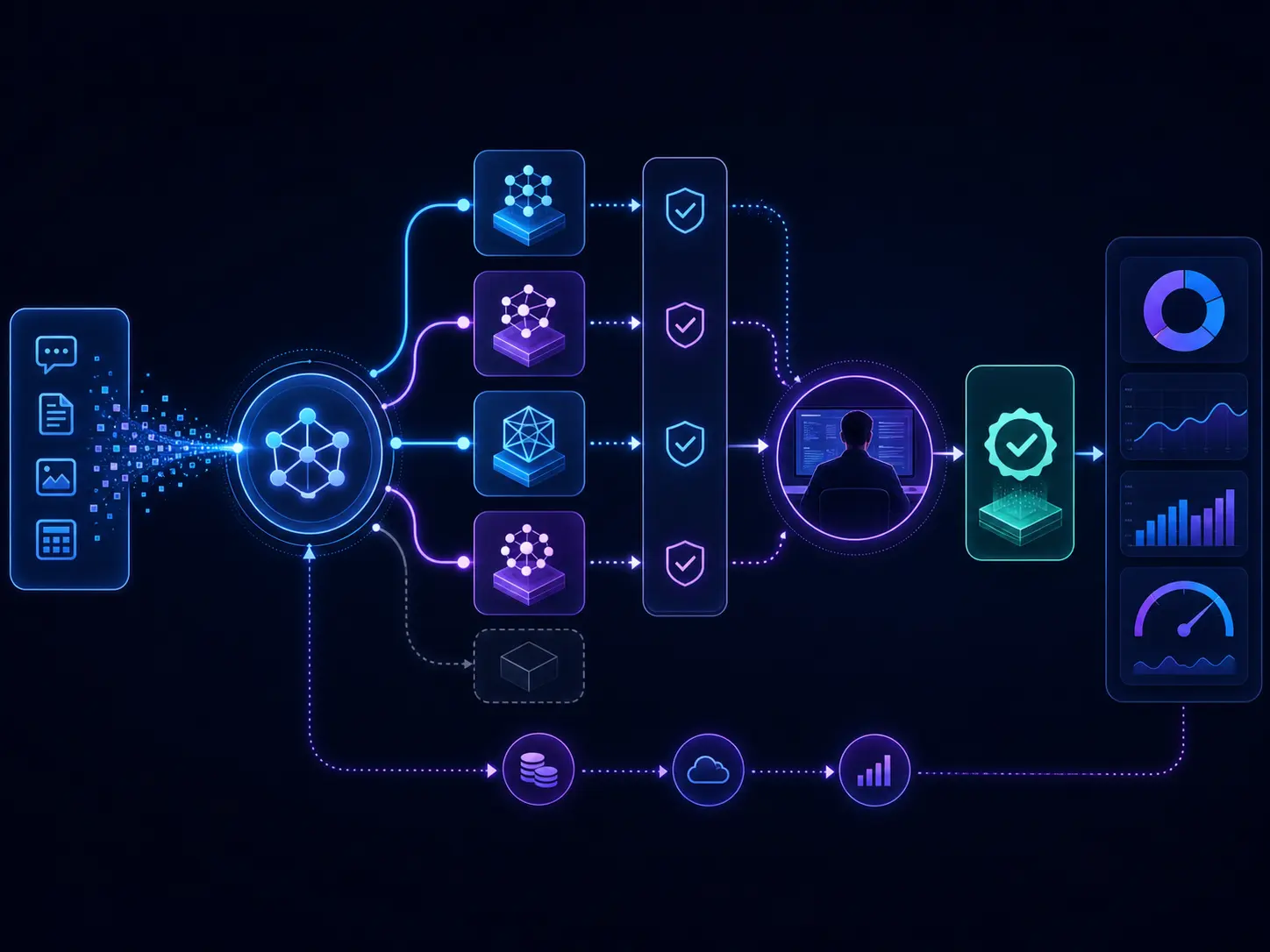 AI FinOps workflow showing task classification, LLM routing, quality gates, human review, and cost tracking.
AI FinOps workflow showing task classification, LLM routing, quality gates, human review, and cost tracking.
Human Review Is Part of the Cost Model
Human review is often treated as an inconvenience. In agency operations, it should be treated as a designed part of the workflow.
A reviewer should not redo the whole task. The system should prepare the evidence, show the model’s output, explain the route, and make approval fast.
For example, a review screen for a CRM enrichment workflow might show:
- original lead data;
- matched account records;
- enrichment sources;
- model-generated summary;
- recommended score;
- reason for the recommendation;
- route used;
- confidence score;
- approve, edit, or reject buttons.
That review time is still a cost, but it is much smaller than manual research from scratch. It also gives the agency a stronger quality story: the workflow is not 'AI does everything.' It is 'AI prepares the work, and people approve the parts that matter.'
For high-risk tasks, human review is not optional. It is the mechanism that makes the system acceptable to the client.
AI FinOps Metrics Agencies Should Track
An agency does not need a huge analytics platform on day one, but it does need basic visibility.
Track these metrics per client and per workflow:
| Metric | Why it matters |
|---|---|
| Cost per successful task | Shows real unit economics |
| Cost per failed task | Reveals expensive failure modes |
| Retry rate | Shows prompt, model, or data issues |
| Premium model usage rate | Shows whether routing is working |
| Human review time | Protects margins and pricing assumptions |
| Approval rate | Measures output quality |
| Edit rate | Shows how much cleanup humans still do |
| Escalation rate | Shows risk and ambiguity |
| Latency per route | Helps with user experience and SLA design |
| Gross margin per workflow | Shows whether the service is viable |
The most important metric is usually not the cheapest route. It is the cheapest route that consistently passes review.
Pricing AI Automation Without Dangerous Promises
Agencies should be careful with claims. Do not promise that an AI workflow will replace a team, guarantee revenue, or produce fixed savings before measuring the baseline.
A safer pricing model combines:
-
Discovery or audit fee
Paid work to map the workflow, measure the baseline, inspect data quality, and estimate feasibility. -
Implementation fee
Covers integration, routing design, prompt design, evaluation cases, review screens, logging, and deployment. -
Monthly operations fee
Covers monitoring, cost tracking, route updates, model changes, bug fixes, reporting, and support. -
Usage tier
Protects the agency when volume grows or edge cases increase. -
Optional outcome component
Can be used only when the baseline and attribution are clear.
This structure is more professional than selling 'AI automation' as a vague package. It also makes client conversations easier because every part of the price maps to real work and real risk.
Example: Legal Intake Automation
Consider a legal intake workflow for a firm that receives vendor contracts, policy documents, NDAs, and client forms. Before automation, a paralegal reads the document, categorizes it, extracts important fields, checks whether it matches standard policy, and routes it to the right reviewer.
A routing plan might look like this:
- small model for document type classification;
- structured extraction for names, dates, parties, jurisdiction, and document category;
- retrieval over internal policy guidance;
- stronger model for clause summaries and unusual terms;
- required human review before any legal recommendation is sent to a client or attorney.
The business case is not that AI replaces legal judgment. The business case is that expensive human time is spent on review and exceptions instead of first-pass sorting.
The agency’s margin depends on the route. If every document goes straight to a premium model with a long context window, the cost profile becomes hard to control. If routine documents are classified cheaply, long documents are summarized before deeper analysis, and unusual cases are escalated, the workflow becomes easier to price, explain, and maintain.
Example: Support Triage Automation
Support triage is often a better first AI FinOps project than legal intake because the risk is lower and the volume is higher.
A support workflow might include:
- Classify the ticket by product area.
- Detect urgency and customer tier.
- Retrieve related documentation.
- Summarize the issue.
- Suggest priority.
- Draft an internal note.
- Escalate if the customer is high-value, angry, or reporting a possible incident.
Cheap models may handle classification and formatting. Stronger models may handle complex summaries or ambiguous incidents. Human review may be required before sending external replies.
This is a good workflow for agencies because the outcome is measurable: reduced first-response time, better routing consistency, lower backlog, and less manual triage work.
Mistakes That Destroy AI Agency Margins
Most margin problems are not caused by model prices alone. They are caused by weak workflow design.
Common mistakes include:
- sending every task to a premium model by default;
- stuffing too much context into every prompt;
- skipping quality gates;
- ignoring review time;
- not tracking retries;
- pricing by vibes instead of task volume;
- allowing scope creep after deployment;
- building custom workflows with no reusable components;
- promising savings before measuring the baseline;
- optimizing for cost while quality quietly falls.
The fix is not one clever prompt. The fix is operating discipline: logs, route maps, evaluation sets, cost reports, human review, and clear pricing boundaries.
How to Build the First AI FinOps Workflow
Start with one workflow where the baseline is easy to measure.
A good first workflow has:
- enough volume to matter;
- clear input data;
- a repeatable output;
- low or medium error risk;
- a human review path;
- a clear business metric.
Good examples include lead enrichment, support triage, meeting summary distribution, invoice intake, CRM cleanup, internal knowledge search, and weekly reporting.
Build it in stages:
- Measure the current workflow.
- Define the accepted output.
- Create test cases from real examples.
- Choose the initial model route.
- Add quality gates.
- Add review for risky outputs.
- Track cost per successful task.
- Adjust routing only after measuring quality.
Do not start by trying to build a universal agent platform. Start with one workflow that can be measured, improved, and priced.
Conclusion: AI Margin Comes from Operations, Not Hype
AI FinOps is what turns AI automation from a demo into a service business.
For agencies, the advantage is not simply finding a cheaper model. Model prices will keep changing. New models will appear. Clients will ask for more complex workflows. The durable advantage is the ability to route tasks intelligently, control context, monitor cost, measure quality, use human review where it matters, and price the work responsibly.
The best AI automation agencies will not sell magic. They will sell reliable workflow outcomes with visible economics.
Start with cost per task. Add routing. Add quality gates. Add review. Track the real margin. That is how AI services become sustainable.